♥常见排序算法知识体系详解♥
本章主要介绍排序总结。@pdai
知识体系文章
知识体系系统性梳理
相关文章
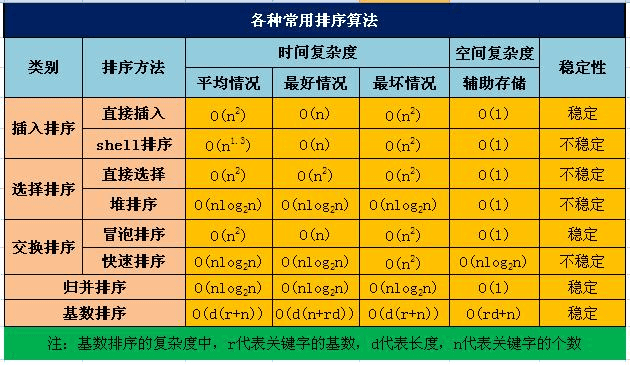
A. 常见排序概要:重点理解几个排序之间的对比,时间和空间复杂度,以及应用。PS:越简单越要提高认知效率,做到战略上藐视战术上重视。
B. 常见排序详解:具体分析各种排序及其复杂度,查漏补缺;在综合复杂度及稳定性情况下,通常
希尔,快排和归并需要重点掌握。
- 排序 - 冒泡排序(Bubble Sort)
- 它是一种较简单的排序算法。它会遍历若干次要排序的数列,每次遍历时,它都会从前往后依次的比较相邻两个数的大小;如果前者比后者大,则交换它们的位置。这样,一次遍历之后,最大的元素就在数列的末尾! 采用相同的方法再次遍历时,第二大的元素就被排列在最大元素之前。重复此操作,直到整个数列都有序为止
- 排序 - 快速排序(Quick Sort)
- 它的基本思想是: 选择一个基准数,通过一趟排序将要排序的数据分割成独立的两部分;其中一部分的所有数据都比另外一部分的所有数据都要小。然后,再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
- 排序 - 插入排序(Insertion Sort)
- 直接插入排序(Straight Insertion Sort)的基本思想是: 把n个待排序的元素看成为一个有序表和一个无序表。开始时有序表中只包含1个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,将它插入到有序表中的适当位置,使之成为新的有序表,重复n-1次可完成排序过程。
- 排序 - Shell排序(Shell Sort)
- 希尔排序实质上是一种分组插入方法。它的基本思想是: 对于n个待排序的数列,取一个小于n的整数gap(gap被称为步长)将待排序元素分成若干个组子序列,所有距离为gap的倍数的记录放在同一个组中;然后,对各组内的元素进行直接插入排序。 这一趟排序完成之后,每一个组的元素都是有序的。然后减小gap的值,并重复执行上述的分组和排序。重复这样的操作,当gap=1时,整个数列就是有序的。
- 排序 - 选择排序(Selection sort)
- 它的基本思想是: 首先在未排序的数列中找到最小(or最大)元素,然后将其存放到数列的起始位置;接着,再从剩余未排序的元素中继续寻找最小(or最大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
- 排序 - 堆排序(Heap Sort)
- 堆排序是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
- 排序 - 归并排序(Merge Sort)
- 将两个的有序数列合并成一个有序数列,我们称之为"归并"。归并排序(Merge Sort)就是利用归并思想对数列进行排序。
- 排序 - 桶排序(Bucket Sort)
- 桶排序(Bucket Sort)的原理很简单,将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)
- 排序 - 基数排序(Radix Sort)
- 它的基本思想是: 将整数按位数切割成不同的数字,然后按每个位数分别比较。具体做法是: 将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列
学习推荐
学习排序 - 动画展示排序
整体性比较好系列 - @skywang12345
不同情况下排序选择
在不同的情形下,排序速度前三名也不尽相同:
| 排序场景 | 排序效率 |
|---|---|
| Random | 希尔>快排>归并 |
| Few unique | 快排>希尔>归并 |
| Reversed | 快排>希尔>归并 |
| Almost sorted | 插入排序>基数排序>快排>希尔>归并 |
总结来看: 快速排序和希尔排序在排序速度上表现是比较优秀的,而归并排序稍微次之.
参考文章
- https://www.cnblogs.com/hokky/p/8529042.html