字符串匹配 - 文本预处理:后缀树(Suffix Tree)
上述字符串匹配算法(朴素的字符串匹配算法, KMP 算法, Boyer-Moore算法)均是通过对模式(Pattern)字符串进行预处理的方式来加快搜索速度。对 Pattern 进行预处理的最优复杂度为 O(m),其中 m 为 Pattern 字符串的长度。那么,有没有对文本(Text)进行预处理的算法呢?本文即将介绍一种对 Text 进行预处理的字符串匹配算法:后缀树(Suffix Tree)。@pdai
什么是后缀树
上述字符串匹配算法(朴素的字符串匹配算法, KMP 算法, Boyer-Moore算法)均是通过对模式(Pattern)字符串进行预处理的方式来加快搜索速度。对 Pattern 进行预处理的最优复杂度为 O(m),其中 m 为 Pattern 字符串的长度。那么,有没有对文本(Text)进行预处理的算法呢?本文即将介绍一种对 Text 进行预处理的字符串匹配算法:后缀树(Suffix Tree)。
后缀树的性质:
- 存储所有 n(n-1)/2 个后缀需要 O(n) 的空间,n 为的文本(Text)的长度;
- 构建后缀树需要 O(dn) 的时间,d 为字符集的长度(alphabet);
- 对模式(Pattern)的查询需要 O(dm) 时间,m 为 Pattern 的长度;
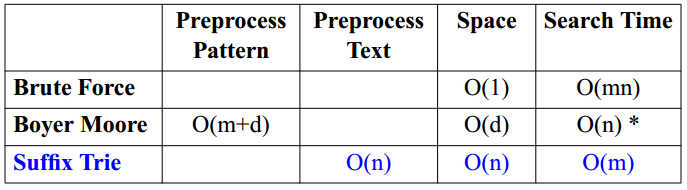
在《字典树(前缀树)》一文中,介绍了一种特殊的树状信息检索数据结构:字典树(Trie)。Trie 将关键词中的字符按顺序添加到树中的节点上,这样从根节点开始遍历,就可以确定指定的关键词是否存在于 Trie 中。
下面是根据集合 {bear, bell, bid, bull, buy, sell, stock, stop} 所构建的 Trie 树。
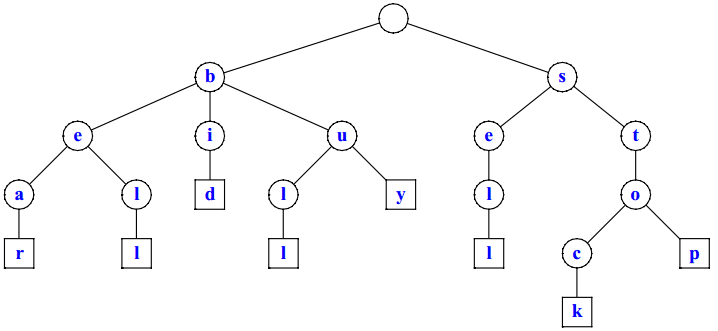
我们观察上面这颗 Trie,对于关键词 "bear",字符 "a" 和 "r" 所在的节点没有其他子节点,所以可以考虑将这两个节点合并,如下图所示。
这样,我们就得到了一棵压缩过的 Trie,称为压缩字典树(Compressed Trie)。
而后缀树(Suffix Tree)则首先是一棵 Compressed Trie,其次,后缀树中存储的关键词为所有的后缀。这样,实际上我们也就得到了构建后缀树的抽象过程:
- 根据文本 Text 生成所有后缀的集合;
- 将每个后缀作为一个单独的关键词,构建一棵 Compressed Trie。
比如,对于文本 "banana\0",其中 "\0" 作为文本结束符号。下面是该文本所对应的所有后缀。
banana\0
anana\0
nana\0
ana\0
na\0
a\0
\0
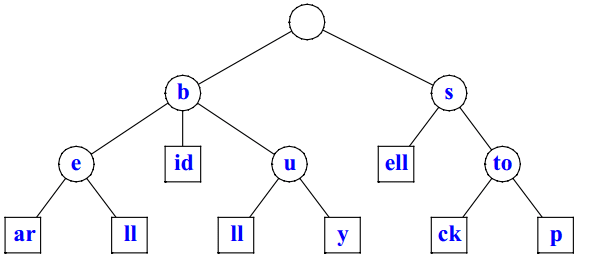
将每个后缀作为一个关键词,构建一棵 Trie。
然后,将独立的节点合并,形成 Compressed Trie。
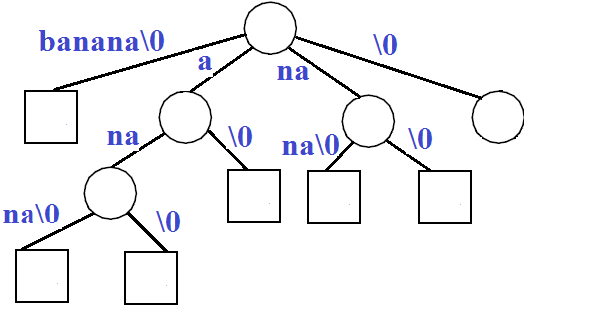
则上面这棵树就是文本 "banana\0" 所对应的后缀树。
现在我们先熟悉两个概念:显式后缀树(Explicit Suffix Tree)和隐式后缀树(Implicit Suffix Tree)。
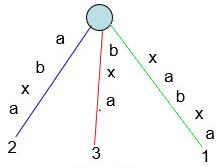
下面用字符串 "xabxa" 举例说明两者的区别,其包括后缀列表如下。
xabxa
abxa
bxa
xa
a
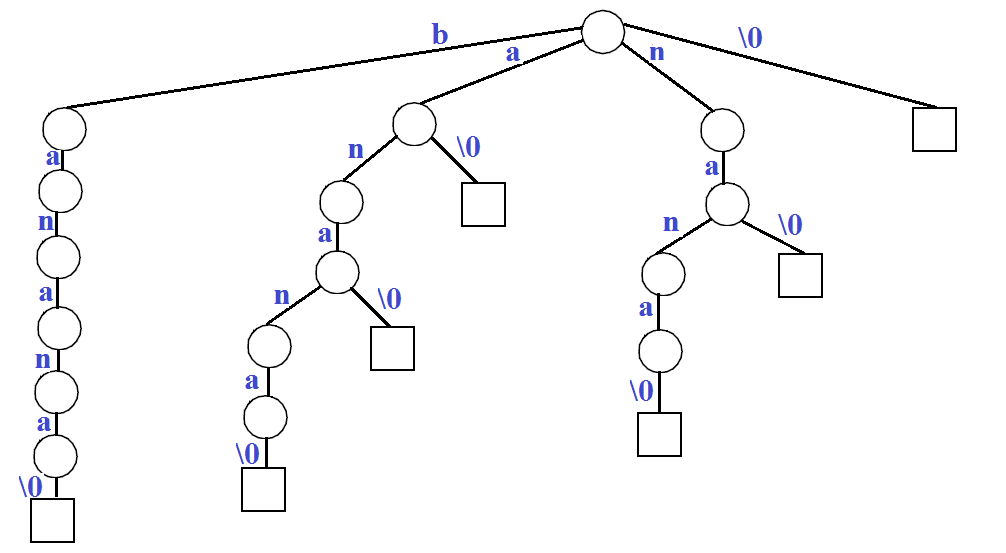
我们发现,后缀 "xa" 和 "a" 已经分别包含在后缀 "xabxa" 和 "abxa" 的前缀中,这样构造出来的后缀树称为隐式后缀树(Implicit Suffix Tree)。
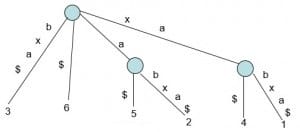
而如果不希望这样的情形发生,可以在每个后缀的结尾加上一个特殊字符,比如 "$" 或 "#" 等,这样我们就可以使得后缀保持唯一性。
xabxa$
abxa$
bxa$
xa$
a$
$
在 1995 年,Esko Ukkonen 发表了论文《On-line construction of suffix trees》,描述了在线性时间内构建后缀树的方法。下面尝试描述 Ukkonen 算法的基本实现原理,从简单的字符串开始描述,然后扩展到更复杂的情形。
Suffix Tree 与 Trie 的不同在于,边(Edge)不再只代表单个字符,而是通过一对整数 [from, to] 来表示。其中 from 和 to 所指向的是 Text 中的位置,这样每个边可以表示任意的长度,而且仅需两个指针,耗费 O(1) 的空间。
首先,我们从一个最简单的字符串 Text = "abc" 开始实践构建后缀树,"abc" 中没有重复字符,使得构建过程更简单些。构建过程的步骤是:从左到右,对逐个字符进行操作。
abc
第 1 个字符是 "a",创建一条边从根节点(root)到叶节点,以 [0, #] 作为标签代表其在 Text 中的位置从 0 开始。使用 "#" 表示末尾,可以认为 "#" 在 "a" 的右侧,位置从 0 开始,则当前位置 "#" 在 1 位。
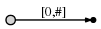
其代表的后缀意义如下。
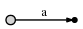
第 1 个字符 "a" 处理完毕,开始处理第 2 个字符 "b"。涉及的操作包括:
- 扩展已经存在的边 "a" 至 "ab";
- 插入一条新边以表示 "b";
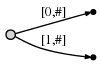
其代表的后缀意义如下。
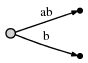
这里,我们观察到了两点:
- "ab" 边的表示 [0, #] 与之前是相同的,当 "#" 位置由 1 挪至 2 时,[0, #] 所代表的意义自动地发生了改变。
- 每条边的空间复杂度为 O(1),即只消耗两个指针,而与边所代表的字符数量无关;
接着再处理第 3 个字符 "c",重复同样的操作,"#" 位置向后挪至第 3 位:
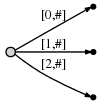
其代表的后缀意义如下。
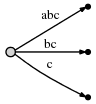
此时,我们观察到:
- 经过上面的步骤后,我们得到了一棵正确的后缀树;
- 操作步骤的数量与 Text 中的字符的数量一样多;
- 每个步骤的工作量是 O(1),因为已存在的边都是依据 "#" 的挪动而自动更改的,仅需为最后一个字符添加一条新边,所以时间复杂度为 O(1)。则,对于一个长度为 n 的 Text,共需要 O(n) 的时间构建后缀树。
当然,我们进展的这么顺利,完全是因为所操作的字符串 Text = "abc" 太简单,没有任何重复的字符。那么现在我们来处理一个更复杂一些的字符串 Text = "abcabxabcd"。
abcabxabcd
同上面的例子类似的是,这个新的 Text 同样以 "abc" 开头,但其后接着 "ab","x","abc","d" 等,并且出现了重复的字符。
前 3 个字符 "abc" 的操作步骤与上面介绍的相同,所以我们会得到下面这颗树:
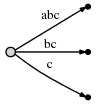
当 "#" 继续向后挪动一位,即第 4 位时,隐含地意味着已有的边会自动的扩展为:
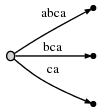
即 [0, #], [1, #], [2, #] 都进行了自动的扩展。按照上面的逻辑,此时应该为剩余后缀 "a" 创建一条单独的边。但,在做这件事之前,我们先引入两个概念。
- 活动点(active point),是一个三元组,包括(active_node, active_edge, active_length);
- 剩余后缀数(remainder),是一个整数,代表着还需要插入多少个新的后缀;
如何使用这两个概念将在下面逐步地说明。不过,现在我们可以先确定两件事:
- 在 Text = "abc" 的例子中,活动点(active point)总是 (root, '\0x', 0)。也就是说,活动节点(active_node)总是根节点(root),活动边(active_edge)是空字符 '\0x' 所指定的边,活动长度(active_length)是 0。
- 在每个步骤开始时,剩余后缀数(remainder)总是 1。意味着,每次我们要插入的新的后缀数目为 1,即最后一个字符。
# = 3, active_point = (root, '\0x', 1), remainder = 1
当处理第 4 字符 "a" 时,我们注意到,事实上已经存在一条边 "abca" 的前缀包含了后缀 "a"。在这种情况下:
- 我们不再向 root 插入一条全新的边,也就是 [3, #]。相反,既然后缀 "a" 已经被包含在树中的一条边上 "abca",我们保留它们原来的样子。
- 设置 active point 为 (root, 'a', 1),也就是说,active_node 仍为 root,active_edge 为 'a',active_length 为 1。这就意味着,活动点现在是从根节点开始,活动边是以 'a' 开头的某个边,而位置就是在这个边的第 1 位。这个活动边的首字符为 'a',实际上,仅会有一个边是以一个特定字符开头的。
- remainder 的值需要 +1,也就是 2。
# = 4, active_point = (root, 'a', 1), remainder = 2
此时,我们还观察到:当我们要插入的后缀已经存在于树中时,这颗树实际上根本就没有改变,我们仅修改了 active point 和 remainder。那么,这颗树也就不再能准确地描述当前位置了,不过它却正确地包含了所有的后缀,即使是通过隐式的方式(Implicitly)。因此,处理修改变量,这一步没有其他工作,而修改变量的时间复杂度为 O(1)。
继续处理下一个字符 "b","#" 继续向后挪动一位,即第 5 位时,树被自动的更新为:
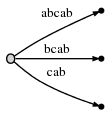
由于剩余后缀数(remainder)的值为 2,所以在当前位置,我们需要插入两个最终后缀 "ab" 和 "b"。这是因为:
- 前一步的 "a" 实际上没有被真正的插入到树中,所以它被遗留了下来(remained),然而我们又向前迈了一步,所以它现在由 "a" 延长到 "ab";
- 还有就是我们需要插入新的最终后缀 "b";
实际操作时,我们就是修改 active point,指向 "a" 后面的位置,并且要插入新的最终后缀 "b"。但是,同样的事情又发生了,"b" 事实上已经存在于树中一条边 "bcab" 的前缀上。那么,操作可以归纳为:
- 修改活动点为 (root, 'a', 2),实际还是与之前相同的边,只是将指向的位置向后挪到 "b",修改了 active_length,即 "ab"。
- 增加剩余后缀数(remainder)为 3,因为我们又没有为 "b" 插入全新的边。
# = 5, active_point = (root, 'a', 2), remainder = 3
再具体一点,我们本来准备插入两个最终后缀 "ab" 和 "b",但因为 "ab" 已经存在于其他的边的前缀中,所以我们只修改了活动点。对于 "b",我们甚至都没有考虑要插入,为什么呢?因为如果 "ab" 存在于树中,那么他的每个后缀都一定存在于树中。虽然仅仅是隐含性的,但却一定存在,因为我们一直以来就是按照这样的方式来构建这颗树的。
继续处理下一个字符 "x","#" 继续向后挪动一位,即第 6 位时,树被自动的更新为:
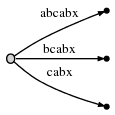
由于剩余后缀数(Remainder)的值为 3,所以在当前位置,我们需要插入 3 个最终后缀 "abx", "bx" 和 "x"。
活动点告诉了我们之前 "ab" 结束的位置,所以仅需跳过这一位置,插入新的 "x" 后缀。"x" 在树中还不存在,因此我们分裂 "abcabx" 边,插入一个内部节点:
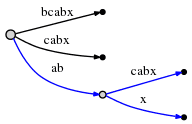
分裂和插入新的内部节点耗费 O(1) 时间。
现在,我们已经处理了 "abx",并且把 remainder 减为 2。然后继续插入下一个后缀 "bx",但做这个操作之前需要先更新活动点,这里我们先做下部分总结。
对于上面对边的分裂和插入新的边的操作,可以总结为 Rule 1,其应用于当 active_node 为 root 节点时。
Rule 1
当向根节点插入时遵循:
- active_node 保持为 root;
- active_edge 被设置为即将被插入的新后缀的首字符;
- active_length 减 1;
因此,新的活动点为 (root, 'b', 1),表明下一个插入一定会发生在边 "bcabx" 上,在 1 个字符之后,即 "b" 的后面。
# = 6, active_point = (root, 'b', 1), remainder = 2
我们需要检查 "x" 是否在 "b" 后面出现,如果出现了,就是我们上面见到过的样子,可以什么都不做,只更新活动点。如果未出现,则需要分裂边并插入新的边。
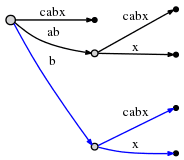
同样,这次操作也花费了 O(1) 时间。然后将 remainder 更新为 1,依据 Rule 1 活动点更新为 (root, 'x', 0)。
# = 6, active_point = (root, 'x', 0), remainder = 1
此时,我们将归纳出 Rule 2。
Rule 2
- 如果我们分裂(Split)一条边并且插入(Insert)一个新的节点,并且如果该新节点不是当前步骤中创建的第一个节点,则将先前插入的节点与该新节点通过一个特殊的指针连接,称为后缀连接(Suffix Link)。后缀连接通过一条虚线来表示。
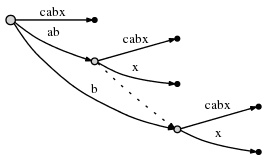
继续上面的操作,插入最终后缀 "x"。因为活动点中的 active_length 已经降到 0,所以插入操作将发生在 root 上。由于没有以 "x" 为前缀的边,所以插入一条新的边:
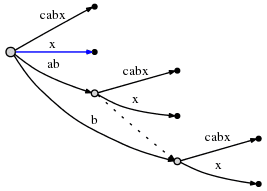
这样,这一步骤中的所有操作就完成了。
# = 6, active_point = (root, '\0x', 0), remainder = 1
继续处理下一个字符 "a","#" 继续向后挪动一位。发现后缀 "a" 已经存在于数中的边中,所以仅更新 active point 和 remainder。
# = 7, active_point = (root, 'a', 1), remainder = 2
继续处理下一个字符 "b","#" 继续向后挪动一位。发现后缀 "ab" 和 "b" 都已经存在于树中,所以仅更新 active point 和 remainder。这里我们先称 "ab" 所在的边的节点为 node1。
# = 8, active_point = (root, 'a', 2), remainder = 3
继续处理下一个字符 "c","#" 继续向后挪动一位。此时由于 remainder = 3,所以需要插入 "abc","bc","c" 三个后缀。"c" 实际上已经存在于 node1 后的边上。
# = 9, active_point = (node1, 'c', 1), remainder = 4
继续处理下一个字符 "d","#" 继续向后挪动一位。此时由于 remainder = 4,所以需要插入 "abcd","bcd","cd","d" 四个后缀。

上图中的 active_node,当节点准备分裂时,被标记了红色。则归纳出了 Rule 3。
Rule 3
- 当从 active_node 不为 root 的节点分裂边时,我们沿着后缀连接(Suffix Link)的方向寻找节点,如果存在一个节点,则设置该节点为 active_noe;如果不存在,则设置 active_node 为 root。active_edge 和 active_length 保持不变。
所以,现在活动点为 (node2, 'c', 1),其中 node2 为下图中的红色节点:
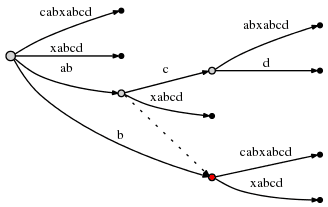
# = 10, active_point = (node2, 'c', 1), remainder = 3
由于对 "abcd" 的插入已经完成,所以将 remainder 的值减至 3,并且开始处理下一个剩余后缀 "bcd"。此时需要将边 "cabxabcd" 分裂,然后插入新的边 "d"。根据 Rule 2,我们需要在之前插入的节点与当前插入的节点间创建一条新的后缀连接。
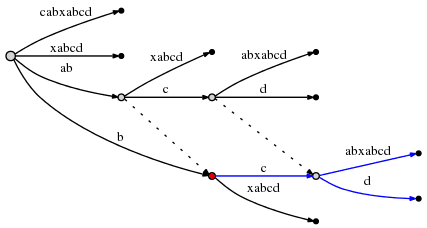
此时,我们观察到,后缀连接(Suffix Link)让我们能够重置活动点,使得对下一个后缀的插入操作仅需 O(1) 时间。从上图也确认了,"ab" 连接的是其后缀 "b",而 "abc" 连接的是其后缀 "bc"。
当前操作还没有完成,因为 remainder 是 2,根绝 Rule 3 我们需要重新设置活动点。因为上图中的红色 active_node 没有后缀连接(Suffix Link),所以活动点被设置为 root,也就是 (root, 'c', 1)。
# = 10, active_point = (root, 'c', 1), remainder = 2
因此,下一个插入操作 "cd" 将从 Root 开始,寻找以 "c" 为前缀的边 "cabxabcd",这也引起又一次分裂:
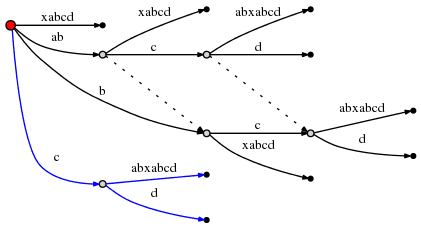
由于此处又创建了一个新的内部节点,依据 Rule 2,我们需要建立一条与前一个被创建内节点的后缀连接。

然后,remainder 减为 1,active_node 为 root,根据 Rule 1 则活动点为 (root, 'd', 0)。也就是说,仅需在根节点上插入一条 "d" 新边。
# = 10, active_point = (root, 'd', 0), remainder = 1
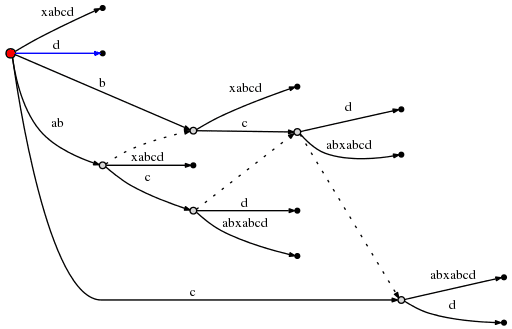
整个步骤完成。
总体上看,我们有一系列的观察结果:
- 在每一步中将 "#" 向右移动 1 位时,所有叶节点自动更新的时间为 O(1);
- 但实际上并没有处理这两种情况:
- 从前一步中遗留的后缀;
- 当前步骤中的最终字符;
- remainder 告诉了我们还余下多少后缀需要插入。这些插入操作将逐个的与当前位置 "#" 之前的后缀进行对应,我们需要一个接着一个的处理。更重要的是,每次插入需要 O(1) 时间,活动点准确地告诉了我们改如何进行,并且也仅需在活动点中增加一个单独的字符。为什么?因为其他字符都隐式地被包含了,要不也就不需要 active point 了。
- 每次插入之后,remainder 都需要减少,如果存在后缀连接(Suffix Link)的话就续接至下一个节点,如果不存在则返回值 root 节点(Rule 3)。如果已经是在 root 节点了,则依据 Rule 1 来修改活动点。无论哪种情况,仅需 O(1) 时间。
- 如果这些插入操作中,如果发现要被插入的字符已经存在于树中,则什么也不做,即使 remainder > 0。原因是要被插入的字符实际上已经隐式地被包含在了当前的树中。而 remainder > 0 则确保了在后续的操作中会进行处理。
- 那么如果在算法结束时 remainder > 0 该怎么办?这种情况说明了文本的尾部字符串在之前某处已经出现过。此时我们需要在尾部添加一个额外的从未出现过的字符,通常使用 "$" 符号。为什么要这么做呢?如果后续我们用已经完成的后缀树来查找后缀,匹配结果一定要出现在叶子节点,否则就会出现很多假匹配,因为很多字符串已经被隐式地包含在了树中,但实际并不是真正的后缀。同时,最后也强制 remainder = 0,以此来保证所有的后缀都形成了叶子节点。尽管如此,如果想用后缀树搜索常规的子字符串,而不仅是搜索后缀,这么做就不是必要的了。
- 那么整个算法的复杂度是多少呢?如果 Text 的长度为 n,则有 n 步需要执行,算上 "$" 则有 n+1 步。在每一步中,我们要么什么也不做,要么执行 remainder 插入操作并消耗 O(1) 时间。因为 remainder 指示了在前一步中我们有多少无操作次数,在当前步骤中每次插入都会递减,所以总体的数量还是 n。因此总体的复杂度为 O(n)。
- 然而,还有一小件事我还没有进行适当的解释。那就是,当我们续接后缀连接时,更新 active point,会发现 active_length 可能与 active_node 协作的并不好。例如下面这种情况:
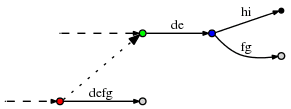
假设 active point 是红色节点 (red, 'd', 3),因此它指向 "def" 边中 "f" 之后的位置。现在假设我们做了必要的更新,而且依据 Rule 3 续接了后缀连接并修改了活动点,新的 active point 是 (green, 'd', 3)。然而从绿色节点出发的 "d" 边是 "de",这条边只有 2 个字符。为了找到合适的活动点,看起来我们需要添加一个到蓝色节点的边,然后重置活动点为 (blue, 'f', 1)。
在最坏的情况下,active_length 可以与 remainder 一样大,甚至可以与 n 一样大。而恰巧这种情况可能刚好在找活动点时发生,那么我们不仅需要跳过一个内部节点,可能是多个节点,最坏的情况是 n 个。由于每步里 remainder 是 O(n),续接了后缀连接之后的对活动点的后续调整也是 O(n),那么是否意味着整个算法潜在需要 O(n2) 时间呢?
我认为不是。理由是如果我们确实需要调整活动点(例如,上图中从绿色节点调整到蓝色节点),那么这就引入了一个拥有自己的后缀连接的新节点,而且 active_length 将减少。当我们沿着后缀连接向下走,就要插入剩余的后缀,且只是减少 active_length,使用这种方法可调整的活动点的数量不可能超过任何给定时刻的 active_length。由于 active_length 从来不会超过 remainder,而 remainder 不仅在每个单一步骤里是 O(n),而且对整个处理过程进行的 remainder 递增的总数也是 O(n),因此调整活动点的数目也就限制在了 O(n)。
参考文章
- https://www.cs.helsinki.fi/u/ukkonen/SuffixT1withFigs.pdf
- https://www.cnblogs.com/gaochundong/p/suffix_tree.html
- https://blog.csdn.net/v_july_v/article/details/6897097