分布式系统 - 分布式任务及实现方案
本文主要介绍定时任务的基础和单体方式下定时任务方案的演化,以及常见的分布式任务方案和技术实现要点。@pdai
定时任务和分布式任务介绍
主要介绍定时任务及其方案和演化。
定时任务应用场景
比如每天/每周/每月生成日志汇总,定时发送推送信息,定时生成数据表格等
定时任务的基础
Cron表达式是定时任务的基础。Cron表达式是一个字符串,字符串以5或6个空格隔开,分为6或7个域,每一个域代表一个含义,Cron有如下两种语法格式:
- Seconds Minutes Hours DayofMonth Month DayofWeek Year
- Seconds Minutes Hours DayofMonth Month DayofWeek
具体可以看如下文章:
- CRON表达式 - CRON表达式介绍和使用
- 定时任务和CRON表达式在开发中使用也非常广泛,本文整理了CRON表达式和常见使用例子
- CRON表达式 - CRON生成和校验工具
- 本文主要总结常用的在线CRON生成和校验工具,从而高效的写出正确的表达式
单体应用定时任务的演化
单体中定时任务的演化大概如下,(后续章节逐步介绍分布式场景下的方案)
cron+脚本定时任务
- Linux定时任务工具crontb
JDK内置之Timer
JDK内置的Timer, 现在很少被使用。更多内容和集成可以看:SpringBoot集成定时任务 - Timer实现方式
简单示例如下
执行定时任务,延迟1秒开始执行。
@SneakyThrows
public static void timer() {
// start timer
Timer timer = new Timer();
timer.schedule(new TimerTask() {
public void run() {
log.info("timer-task @{}", LocalDateTime.now());
}
}, 1000);
// waiting to process(sleep to mock)
Thread.sleep(3000);
// stop timer
timer.cancel();
}
输出
10:05:47.440 [Timer-0] INFO tech.pdai.springboot.schedule.timer.timertest.TimerTester - timer-task @2021-10-01T20:05:47.436
schedule 和 scheduleAtFixedRate 有何区别?
- schedule:每次执行完当前任务后,然后间隔一个period的时间再执行下一个任务; 当某个任务执行周期大于时间间隔时,依然按照间隔时间执行下个任务,即它保证了任务之间执行的间隔。
- scheduleAtFixedRate:每次执行时间为上一次任务开始起向后推一个period间隔,也就是说下次执行时间相对于上一次任务开始的时间点;按照上述的例子,它保证了总时间段内的任务的执行次数
为什么几乎很少使用Timer这种方式?
Timer底层是使用一个单线来实现多个Timer任务处理的,所有任务都是由同一个线程来调度,所有任务都是串行执行,意味着同一时间只能有一个任务得到执行,而前一个任务的延迟或者异常会影响到之后的任务。
如果有一个定时任务在运行时,产生未处理的异常,那么当前这个线程就会停止,那么所有的定时任务都会停止,受到影响。
JDK内置之ScheduleExecutorService
ScheduledExecutorService是基于线程池的实现方式。更多内容和集成可以看:SpringBoot集成定时任务 - ScheduleExecutorService实现方式
简单案例如下
延迟1秒执行一个进程任务。
@SneakyThrows
public static void schedule() {
ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);
executor.schedule(
new Runnable() {
@Override
@SneakyThrows
public void run() {
log.info("run schedule @ {}", LocalDateTime.now());
}
},
1000,
TimeUnit.MILLISECONDS);
// waiting to process(sleep to mock)
Thread.sleep(10000);
// stop
executor.shutdown();
}
输出
21:07:02.047 [pool-1-thread-1] INFO tech.pdai.springboot.schedule.executorservice.ScheduleExecutorServiceDemo - run schedule @ 2022-03-10T21:07:02.046
为什么用ScheduledExecutorService 代替 Timer?
上文我们说到Timer底层是使用一个单线程来实现多个Timer任务处理的,所有任务都是由同一个线程来调度,所有任务都是串行执行,意味着同一时间只能有一个任务得到执行,而前一个任务的延迟或者异常会影响到之后的任务。
如果有一个定时任务在运行时,产生未处理的异常,那么当前这个线程就会停止,那么所有的定时任务都会停止,受到影响。
而ScheduledExecutorService是基于线程池的,可以开启多个线程进行执行多个任务,每个任务开启一个线程; 这样任务的延迟和未处理异常就不会影响其它任务的执行了。
Netty之HashedWheelTimer
时间轮(Timing Wheel)是George Varghese和Tony Lauck在1996年的论文'Hashed and Hierarchical Timing Wheels: data structures to efficiently implement a timer facility'实现的,它在Linux内核中使用广泛,是Linux内核定时器的实现方法和基础之一。
时间轮(Timing Wheel)是一种环形的数据结构,就像一个时钟可以分成很多格子(Tick),每个格子代表时间的间隔,它指向存储的具体任务(timerTask)的一个链表。

以上述在论文中的图片例子,这里一个轮子包含8个格子(Tick), 每个tick是一秒钟;
任务的添加:如果一个任务要在17秒后执行,那么它需要转2轮,最终加到Tick=1位置的链表中。
任务的执行:在时钟转2Round到Tick=1的位置,开始执行这个位置指向的链表中的这个任务。(# 这里表示剩余需要转几轮再执行这个任务)
- Netty的HashedWheelTimer要解决什么问题
在Netty中的一个典型应用场景是判断某个连接是否idle,如果idle(如客户端由于网络原因导致到服务器的心跳无法送达),则服务器会主动断开连接,释放资源。判断连接是否idle是通过定时任务完成的,但是Netty可能维持数百万级别的长连接,对每个连接去定义一个定时任务是不可行的,所以如何提升I/O超时调度的效率呢?
Netty根据时间轮(Timing Wheel)开发了HashedWheelTimer工具类,用来优化I/O超时调度(本质上是延迟任务);之所以采用时间轮(Timing Wheel)的结构还有一个很重要的原因是I/O超时这种类型的任务对时效性不需要非常精准。
- HashedWheelTimer的使用方式
通过构造函数看主要参数
public HashedWheelTimer(
ThreadFactory threadFactory,
long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,
long maxPendingTimeouts, Executor taskExecutor) {
}
具体参数说明如下:
threadFactory:线程工厂,用于创建工作线程, 默认是Executors.defaultThreadFactory()tickDuration:tick的周期,即多久tick一次unit: tick周期的单位ticksPerWheel:时间轮的长度,一圈下来有多少格leakDetection:是否开启内存泄漏检测,默认是truemaxPendingTimeouts:最多执行的任务数,默认是-1,即不限制。在高并发量情况下才会设置这个参数。
具体案例请看:SpringBoot集成定时任务 - Netty HashedWheelTimer方式
Spring Tasks
Spring提供的schedule任务,更多内容和集成可以看:SpringBoot集成定时任务 - Spring tasks实现方式
具体使用方式如下:
@EnableScheduling
@Configuration
public class ScheduleDemo {
/**
* 每隔1分钟执行一次。
*/
@Scheduled(fixedRate = 1000 * 60 * 1)
public void runScheduleFixedRate() {
log.info("runScheduleFixedRate: current DateTime, {}", LocalDateTime.now());
}
/**
* 每个整点小时执行一次。
*/
@Scheduled(cron = "0 0 */1 * * ?")
public void runScheduleCron() {
log.info("runScheduleCron: current DateTime, {}", LocalDateTime.now());
}
}
- @Scheduled所支持的参数:
cron:cron表达式,指定任务在特定时间执行;fixedDelay:表示上一次任务执行完成后多久再次执行,参数类型为long,单位ms;fixedDelayString:与fixedDelay含义一样,只是参数类型变为String;fixedRate:表示按一定的频率执行任务,参数类型为long,单位ms;fixedRateString: 与fixedRate的含义一样,只是将参数类型变为String;initialDelay:表示延迟多久再第一次执行任务,参数类型为long,单位ms;initialDelayString:与initialDelay的含义一样,只是将参数类型变为String;zone:时区,默认为当前时区,一般没有用到。
Quartz
来源百度百科, 官网地址:http://www.quartz-scheduler.org/;更多内容和集成可以看:SpringBoot集成定时任务 - 基础quartz实现方式
Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,它可以与J2EE与J2SE应用程序相结合也可以单独使用。Quartz可以用来创建简单或为运行十个,百个,甚至是好几万个Jobs这样复杂的程序。Jobs可以做成标准的Java组件或 EJBs。
它的特点如下
- 纯java实现,可以作为独立的应用程序,也可以嵌入在另一个独立式应用程序运行
- 强大的调度功能,Spring默认的调度框架,灵活可配置;
- 作业持久化,调度环境持久化机制,可以保存并恢复调度现场。系统关闭数据不会丢失;灵活的应用方式,可以任意定义触发器的调度时间表,支持任务和调度各种组合,组件式监听器、各种插件、线程池等功能,多种存储方式等;
- 分布式和集群能力,可以被实例化,一个Quartz集群中的每个节点作为一个独立的Quartz使用,通过相同的数据库表来感知到另一个Quartz应用
Quartz的体系结构
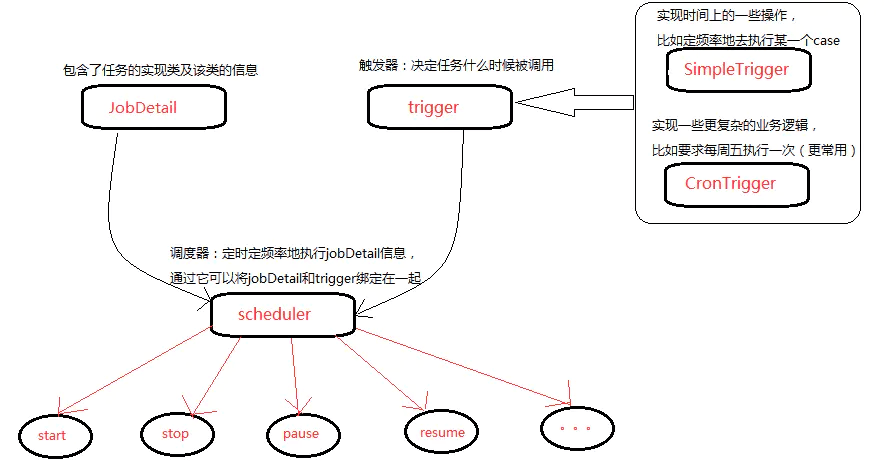
- Job 表示一个工作,要执行的具体内容。
- JobDetail 表示一个具体的可执行的调度程序,Job 是这个可执行程调度程序所要执行的内容,另外 JobDetail 还包含了这个任务调度的方案和策略。
- Trigger 代表一个调度参数的配置,什么时候去调。
- Scheduler 代表一个调度容器,一个调度容器中可以注册多个 JobDetail 和 Trigger。当 Trigger 与 JobDetail 组合,就可以被 Scheduler 容器调度了。
注: 上图来源于https://www.cnblogs.com/jijm123/p/14240320.html
分布式任务的方案
常见的分布式任务的方案有:Quartz Cluster,XXL-Job,Elastic-Job等。@pdai: 综合代码质量,License, 维护方,拓展性等,选择的建议:
- 如果仅是小团队内部自用,可以采用XXL-Job
- 如果是稍大一点的团队,建议使用ElasticJob或者基于ElasticJob进行二次开发
- 如果是团队具备自研能力,可以参考后续的章节(分布式任务的技术要点)设计和自研
Quartz Cluster
Quartz 提供的持久化方式,更多内容和集成可以看: SpringBoot集成定时任务 - 分布式quartz cluster方式
为什么要持久化?
当程序突然被中断时,如断电,内存超出时,很有可能造成任务的丢失。 可以将调度信息存储到数据库里面,进行持久化,当程序被中断后,再次启动,仍然会保留中断之前的数据,继续执行,而并不是重新开始。
Quartz提供了两种持久化方式
Quartz提供两种基本作业存储类型:
- RAMJobStore
在默认情况下Quartz将任务调度的运行信息保存在内存中,这种方法提供了最佳的性能,因为内存中数据访问最快。不足之处是缺乏数据的持久性,当程序路途停止或系统崩溃时,所有运行的信息都会丢失。
- JobStoreTX
所有的任务信息都会保存到数据库中,可以控制事物,还有就是如果应用服务器关闭或者重启,任务信息都不会丢失,并且可以恢复因服务器关闭或者重启而导致执行失败的任务。
XXL-Job
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。实现案例SpringBoot集成定时任务 - 分布式xxl-job方式
如下内容来源于xxl-job官网; 支持如下特性:
- 1、简单:支持通过Web页面对任务进行CRUD操作,操作简单,一分钟上手;
- 2、动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
- 3、调度中心HA(中心式):调度采用中心式设计,“调度中心”自研调度组件并支持集群部署,可保证调度中心HA;
- 4、执行器HA(分布式):任务分布式执行,任务"执行器"支持集群部署,可保证任务执行HA;
- 5、注册中心: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址;
- 6、弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
- 7、触发策略:提供丰富的任务触发策略,包括:Cron触发、固定间隔触发、固定延时触发、API(事件)触发、人工触发、父子任务触发;
- 8、调度过期策略:调度中心错过调度时间的补偿处理策略,包括:忽略、立即补偿触发一次等;
- 9、阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
- 10、任务超时控制:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 11、任务失败重试:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;其中分片任务支持分片粒度的失败重试;
- 12、任务失败告警;默认提供邮件方式失败告警,同时预留扩展接口,可方便的扩展短信、钉钉等告警方式;
- 13、路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
- 14、分片广播任务:执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务;
- 15、动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
- 16、故障转移:任务路由策略选择"故障转移"情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
- 17、任务进度监控:支持实时监控任务进度;
- 18、Rolling实时日志:支持在线查看调度结果,并且支持以Rolling方式实时查看执行器输出的完整的执行日志;
- 19、GLUE:提供Web IDE,支持在线开发任务逻辑代码,动态发布,实时编译生效,省略部署上线的过程。支持30个版本的历史版本回溯。
- 20、脚本任务:支持以GLUE模式开发和运行脚本任务,包括Shell、Python、NodeJS、PHP、PowerShell等类型脚本;
- 21、命令行任务:原生提供通用命令行任务Handler(Bean任务,"CommandJobHandler");业务方只需要提供命令行即可;
- 22、任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔;
- 23、一致性:“调度中心”通过DB锁保证集群分布式调度的一致性, 一次任务调度只会触发一次执行;
- 24、自定义任务参数:支持在线配置调度任务入参,即时生效;
- 25、调度线程池:调度系统多线程触发调度运行,确保调度精确执行,不被堵塞;
- 26、数据加密:调度中心和执行器之间的通讯进行数据加密,提升调度信息安全性;
- 27、邮件报警:任务失败时支持邮件报警,支持配置多邮件地址群发报警邮件;
- 28、推送maven中央仓库: 将会把最新稳定版推送到maven中央仓库, 方便用户接入和使用;
- 29、运行报表:支持实时查看运行数据,如任务数量、调度次数、执行器数量等;以及调度报表,如调度日期分布图,调度成功分布图等;
- 30、全异步:任务调度流程全异步化设计实现,如异步调度、异步运行、异步回调等,有效对密集调度进行流量削峰,理论上支持任意时长任务的运行;
- 31、跨语言:调度中心与执行器提供语言无关的 RESTful API 服务,第三方任意语言可据此对接调度中心或者实现执行器。除此之外,还提供了 “多任务模式”和“httpJobHandler”等其他跨语言方案;
- 32、国际化:调度中心支持国际化设置,提供中文、英文两种可选语言,默认为中文;
- 33、容器化:提供官方docker镜像,并实时更新推送dockerhub,进一步实现产品开箱即用;
- 34、线程池隔离:调度线程池进行隔离拆分,慢任务自动降级进入"Slow"线程池,避免耗尽调度线程,提高系统稳定性;
- 35、用户管理:支持在线管理系统用户,存在管理员、普通用户两种角色;
- 36、权限控制:执行器维度进行权限控制,管理员拥有全量权限,普通用户需要分配执行器权限后才允许相关操作;
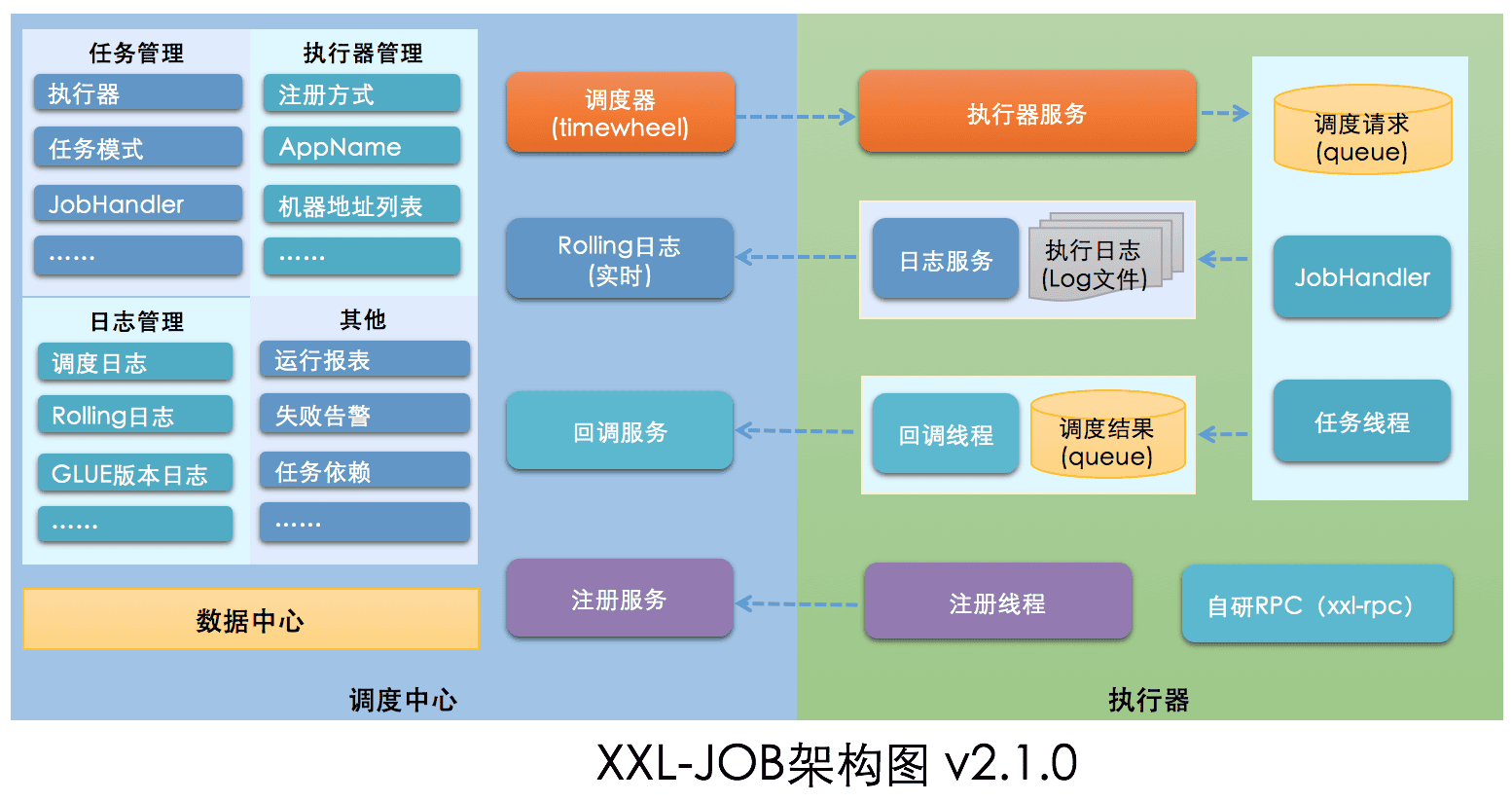
xxl-job的架构设计
设计思想
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
系统组成
- 调度模块(调度中心)
- 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
- 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
- 执行模块(执行器):
- 负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
- 接收“调度中心”的执行请求、终止请求和日志请求等。
架构图
Elastic-Job
ElasticJob 是面向互联网生态和海量任务的分布式调度解决方案,由两个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成。 它通过弹性调度、资源管控、以及作业治理的功能,打造一个适用于互联网场景的分布式调度解决方案,并通过开放的架构设计,提供多元化的作业生态。 它的各个产品使用统一的作业 API,开发者仅需一次开发,即可随意部署。ElasticJob 已于 2020 年 5 月 28 日成为 Apache ShardingSphere 的子项目。
使用 ElasticJob 能够让开发工程师不再担心任务的线性吞吐量提升等非功能需求,使他们能够更加专注于面向业务编码设计; 同时,它也能够解放运维工程师,使他们不必再担心任务的可用性和相关管理需求,只通过轻松的增加服务节点即可达到自动化运维的目的。
ElasticJob-Lite: 定位为轻量级无中心化解决方案,使用 jar 的形式提供分布式任务的协调服务。
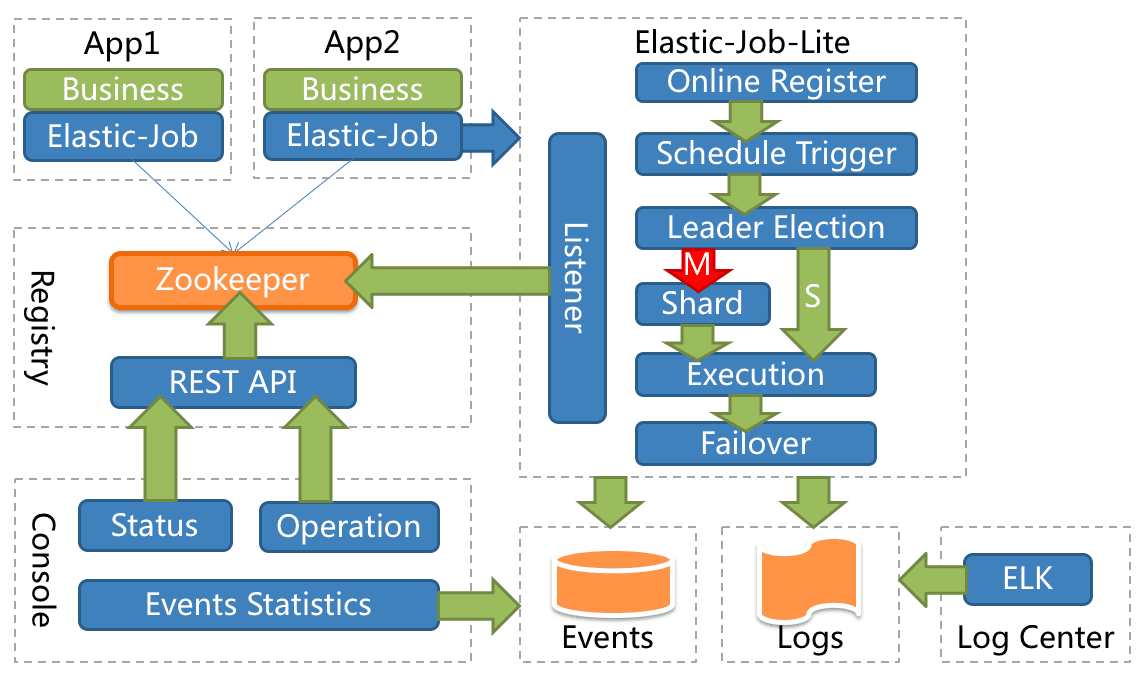
Elasticjob-lite的案例- SpringBoot集成定时任务 - 分布式Elasticjob-lite方式
ElasticJob-Cloud: 采用自研 Mesos Framework 的解决方案,额外提供资源治理、应用分发以及进程隔离等功能。
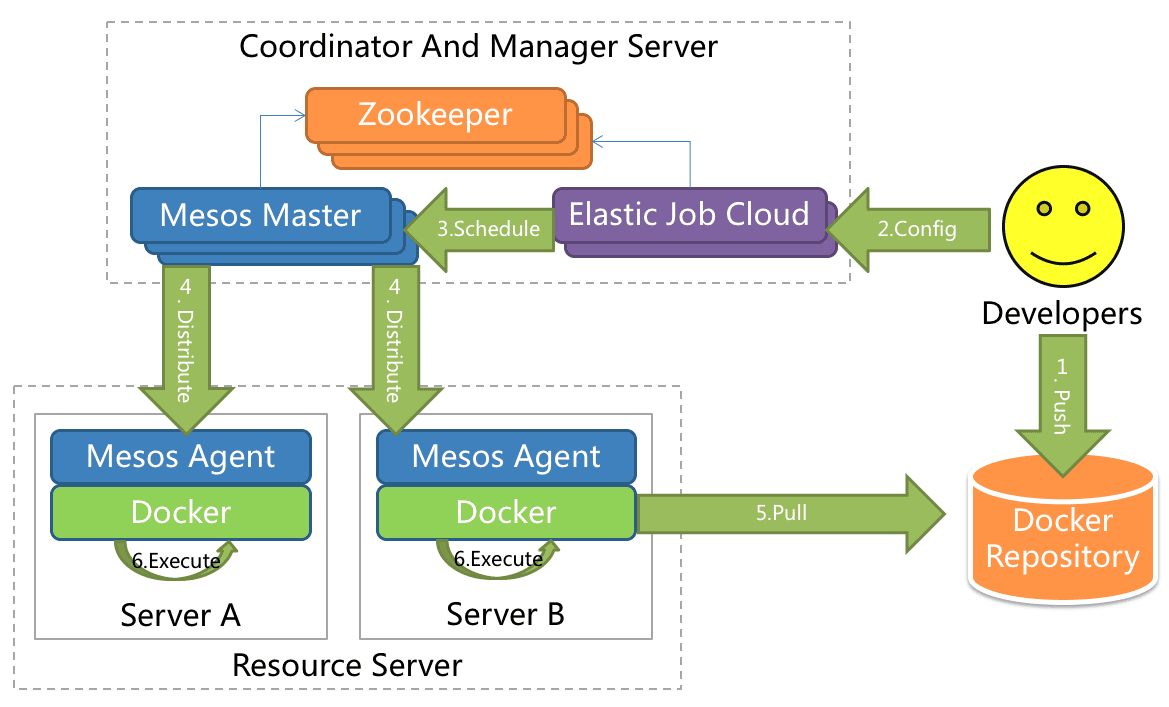
ElasticJob-Lite和ElasticJob-Cloud的区别
| ElasticJob-Lite | ElasticJob-Cloud | |
|---|---|---|
| 无中心化 | 是 | 否 |
| 资源分配 | 不支持 | 支持 |
| 作业模式 | 常驻 | 常驻 + 瞬时 |
| 部署依赖 | ZooKeeper | ZooKeeper + Mesos |
分布式任务的技术要点
站在设计一个分布式任务的中间件的角度看,会需要考虑(结合上述中间件的功能看)哪些功能设计呢? @pdai
基础功能
从基础功能看,主要包括Job类型支持,Job生命周期管理,Job异常处理,接口,拓展性和UI等。
- Job类型支持
- 常规内置类型
- Simple
- Dataflow
- Script
- Http
- 其它语言任务的支持
- Script
- py
- nodejs
- php
- 特殊任务的支持
- 有依赖性的Job,比如有向无环图(DAG)
- 用户拓展的任务
- 通过接口拓展自定任务
- 常规内置类型
- Job生命周期管理
- Add/Remove
- Pause/Resume
- Disable/Enable
- Shutdown
- Job异常处理策略
- LogJobErrorHandler
- ThrowJobErrorHandler
- IgnoreJobErrorHandler
- Message
- EmailJobErrorHandler
- WechatJobErrorHandler
- DingtalkJobErrorHandler
- 接口,拓展性和UI
- 拓展性和API
- 作业 API
- 资源 API
- 监控诊断 API
- 作业监听 API
- UI可视化管理
- 作业管控端
- 作业执行历史数据追踪he
- 注册中心管理
- 拓展性和API
高性能和分布式
从性能和分布式的角度看,主要包括:线程池,分片,Transient Job(分如下具体项),注册中心等
- 线程池
- 分片策略
- AverageAllocationJobShardingStrategy
- OdevitySortByNameJobShardingStrategy
- RotateServerByNameJobShardingStrategy
- Transient Job
- 高可用性(HA)
- 可拓展性(Scale)
- 支持任务在分布式场景下的分片和高可用
- 能够水平扩展任务的吞吐量和执行效率
- 任务处理能力随资源配备弹性伸缩
- 故障转移(Failover)
- 错过作业(Misfire)重新执行
- 幂等(Idempotency)
- 注册中心
- ZooKeeper
生态构建
从生态构建角度看,主要包括 开发拓展接口,三方和平台集成,文档国际化,社区建设等。
- 拓展和接口
- RestAPI
- SPI
- 三方和平台集成
- Spring
- SpringBoot starter
- 日志:与消息平台对接 - ELK
- 报警: 与消息平台对接 - Webchat, DingTalk, Email...
- 监控:与监控平台对接
- 文档国际化
- 社区建设
参考文章
https://shardingsphere.apache.org/elasticjob/current/cn/overview/