Mongo进阶 - DB核心:复制集
在实际的生产环境中,我们需要考虑数据冗余和高可靠性,即通过在不同的机器上保存副本来保证数据的不会因为单点损坏而丢失;能够随时应对数据丢失、机器损坏带来的风险。MongoDB的复制集就是用来解决这个问题的,一组复制集就是一组mongod实例掌管同一个数据集,实例可以在不同的机器上面。实例中包含一个主导,接受客户端所有的写入操作,其他都是副本实例,从主服务器上获得数据并保持同步。@pdai
为什么要引入复制集?
保证数据在生产部署时的冗余和可靠性,通过在不同的机器上保存副本来保证数据的不会因为单点损坏而丢失。能够随时应对数据丢失、机器损坏带来的风险。换一句话来说,还能提高读取能力,用户的读取服务器和写入服务器在不同的地方,而且,由不同的服务器为不同的用户提供服务,提高整个系统的负载。
在MongoDB中就是复制集(replica set): 一组复制集就是一组mongod实例掌管同一个数据集,实例可以在不同的机器上面。实例中包含一个主导,接受客户端所有的写入操作,其他都是副本实例,从主服务器上获得数据并保持同步。
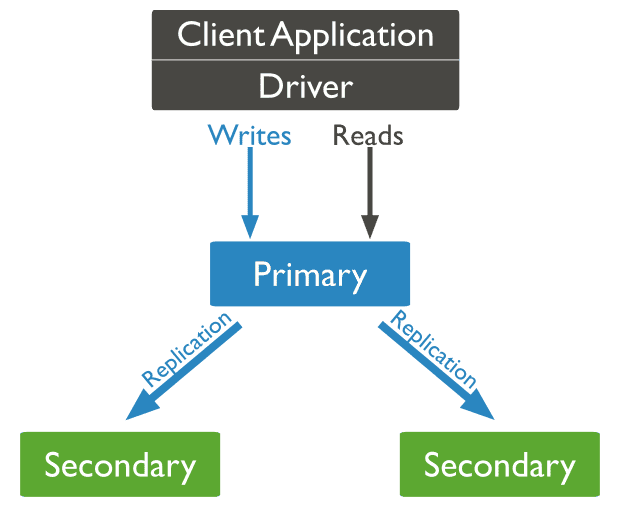
复制集有哪些成员?
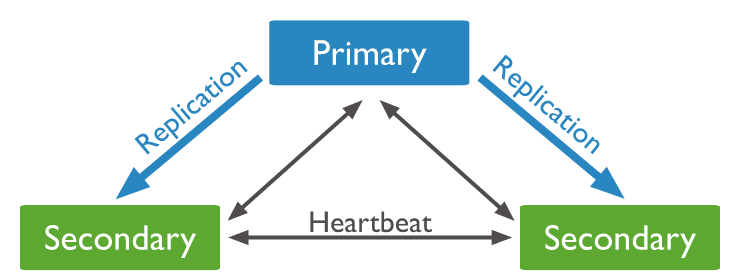
在上图中,我们了解了复制集中的主节点(Primary)和从节点(Secondary), 进一步的我们需要了解更多复制集中的成员,以便深入部署架构和相关配置。
基本成员
让我们看下基本的成员:
- 主节点(Primary)
包含了所有的写操作的日志。但是副本服务器集群包含有所有的主服务器数据,因此当主服务器挂掉了,就会在副本服务器上重新选取一个成为主服务器。
- 从节点(Seconary)
正常情况下,复制集的Seconary会参与Primary选举(自身也可能会被选为Primary),并从Primary同步最新写入的数据,以保证与Primary存储相同的数据。
Secondary可以提供读服务,增加Secondary节点可以提供复制集的读服务能力,同时提升复制集的可用性。另外,Mongodb支持对复制集的Secondary节点进行灵活的配置,以适应多种场景的需求。
- 仲裁节点(Arbiter)
Arbiter节点只参与投票,不能被选为Primary,并且不从Primary同步数据。
比如你部署了一个2个节点的复制集,1个Primary,1个Secondary,任意节点宕机,复制集将不能提供服务了(无法选出Primary),这时可以给复制集添加一个Arbiter节点,即使有节点宕机,仍能选出Primary。
Arbiter本身不存储数据,是非常轻量级的服务,当复制集成员为偶数时,最好加入一个Arbiter节点,以提升复制集可用性。
主节点(Primary)的细化
依据具体功能实现的需要,MongoDB还细化将主节点(Primary)进行了细化:
- Priority0
作为一个辅助可以作为一个备用。在一些复制集中,可能无法在合理的时间内添加新成员的时候。备用成员保持数据的当前最新数据能够替换不可用的成员。
Priority0节点的选举优先级为0,不会被选举为Primary
比如你跨机房A、B部署了一个复制集,并且想指定Primary必须在A机房,这时可以将B机房的复制集成员Priority设置为0,这样Primary就一定会是A机房的成员。

(注意:如果这样部署,最好将『大多数』节点部署在A机房,否则网络分区时可能无法选出Primary)
- Hidden
客户端将不会把读请求分发到隐藏节点上,即使我们设定了 复制集读选项 。
这些隐藏节点将不会收到来自应用程序的请求。我们可以将隐藏节点专用于报表节点或是备份节点。 延时节点也应该是一个隐藏节点。
Hidden节点不能被选为主(Priority为0),并且对Driver不可见。因Hidden节点不会接受Driver的请求,可使用Hidden节点做一些数据备份、离线计算的任务,不会影响复制集的服务。

- Delayed
延时节点的数据集是延时的,因此它可以帮助我们在人为误操作或是其他意外情况下恢复数据。
举个例子,当应用升级失败,或是误操作删除了表和数据库时,我们可以通过延时节点进行数据恢复。

Delayed节点必须是Hidden节点,并且其数据落后与Primary一段时间(可配置,比如1个小时)。
因Delayed节点的数据比Primary落后一段时间,当错误或者无效的数据写入Primary时,可通过Delayed节点的数据来恢复到之前的时间点。
复制集常见部署架构?
我们将从基础三个节点和跨数据中心两个角度看常见复制集的部署架构:
基础三节点
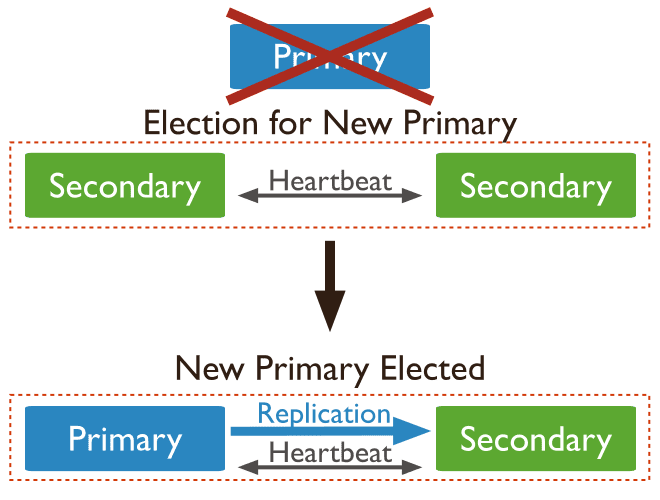
- 一主两从方式
- 一个主节点;
- 两个从节点组成,主节点宕机时,这两个从节点都可以被选为主节点。
当主节点宕机后,两个从节点都会进行竞选,其中一个变为主节点,当原主节点恢复后,作为从节点加入当前的复制集群即可。
- 一主一从一仲裁方式
- 一个主节点
- 一个从节点,可以在选举中成为主节点
- 一个仲裁节点,在选举中,只进行投票,不能成为主节点
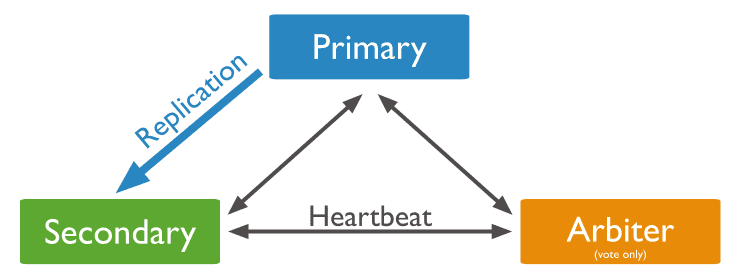
当主节点宕机时,将会选择从节点成为主,主节点修复后,将其加入到现有的复制集群中即可。
跨数据中心
单个数据中心中的复制集易受数据中心故障的影响,比如断电,洪水,断网等;所以多个数据中心便是这么引入的。
为了在数据中心发生故障时保护您的数据,请在备用数据中心中至少保留一个成员。如果可能,请使用奇数个数据中心,并选择成员分布,以最大程度地保证即使丢失数据中心,其余复制集成员也可以构成大多数或最小数量的副本,以提供数据副本。
三个节点
对于三成员复制集,成员的一些可能的分布包括:
- 两个数据中心:两个是数据中心1的成员,一个是数据中心2的成员。如果复制集的成员之一是仲裁者,则将仲裁者与一个承载数据的成员一起分发到数据中心1。
- 如果数据中心1发生故障,则复制集将变为只读。
- 如果数据中心2发生故障,则复制集将保持可写状态,因为数据中心1中的成员可以举行选举。
- 三个数据中心:一个成员是数据中心1,一个成员是数据中心2,一个成员是数据中心3。
- 如果任何数据中心发生故障,复制集将保持可写状态,因为其余成员可以举行选举。
注意
在两个数据中心之间分布复制集成员可提供优于单个数据中心的好处。在两个数据中心分布中,
- 如果其中一个数据中心发生故障,则与单个数据中心分发不同,该数据仍然可供读取。
- 如果具有少数成员的数据中心发生故障,则复制集仍然可以同时执行写操作和读操作。
- 但是,如果具有大多数成员的数据中心发生故障,则复制集将变为只读。
如果可能,请在至少三个数据中心中分配成员。对于配置服务器复制集(CSRS),最佳做法是在三个(或更多,取决于成员的数量)中心之间分布。如果第三个数据中心的成本高得令人望而却步,则一种分配可能性是,在公司政策允许的情况下,在两个数据中心之间平均分配数据承载成员,并将其余成员存储在云中。
五个节点
对于具有5个成员的复制集,成员的一些可能的分布包括(相关注意事项和三个节点一致,这里仅展示分布方案):
- 两个数据中心:数据中心1的三个成员和数据中心2的两个成员。
- 如果数据中心1发生故障,则复制集将变为只读。
- 如果数据中心2发生故障,则复制集将保持可写状态,因为数据中心1中的成员可以创建多数。
- 三个数据中心:两个成员是数据中心1,两个成员是数据中心2,一个成员是站点数据中心3。
- 如果任何数据中心发生故障,复制集将保持可写状态,因为其余成员可以举行选举。
例如,以下5个成员复制集将其成员分布在三个数据中心中。

数据转移的优先级
复制集的某些成员(例如,具有网络限制或资源有限的成员)不应成为故障转移中的主要成员。将不应成为主要成员的成员配置为具priority0。
在某些情况下,您可能希望将一个数据中心中的成员选为主要成员,然后再选择另一数据中心中的成员。您可以修改priority成员的,以使一个数据中心中priority的成员高于 其他数据中心中的成员。
在以下示例中,数据中心1中的复制集成员具有比数据中心2和3中的成员更高的优先级;数据中心2中的成员比数据中心3中的成员具有更高的优先级:

复制集是如何保证数据高可用的?
那么复制集是如何保证数据的高可靠性的呢?或者说它包含有什么机制?这里我们通过两方面阐述:一个是选举机制,另一个是故障转移期间的回滚。
选举机制
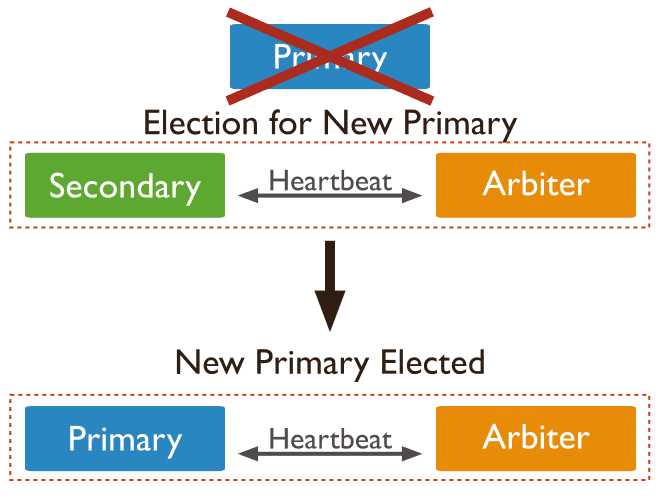
复制集通过选举机制来选择主节点。
- 如何选出Primary主节点的?
假设复制集内能够投票的成员数量为N,则大多数为 N/2 + 1,当复制集内存活成员数量不足大多数时,整个复制集将无法选举出Primary,复制集将无法提供写服务,处于只读状态。
举例:3投票节点需要2个节点的赞成票,容忍选举失败次数为1;5投票节点需要3个节点的赞成票,容忍选举失败次数为2;通常投票节点为奇数,这样可以减少选举失败的概率。
- 在什么情况下会触发选举机制?
在以下的情况将触发选举机制:
往复制集中新加入节点
初始化复制集时
对复制集进行维护时,比如
rs.stepDown()或者rs.reconfig()操作时从节点失联时,比如超时(默认是10秒)
哪些成员具备选举权?哪些没有?
首先不是所有的节点都会参与投票,一个复制集最高可以有50个节点,但是只有7个投票节点。一个非投票节点它的votes是0即vote0; 它的priority是0即priority0。
比如:

同时可投票的节点,必须属于如下状态之一:PRIMARY, SECONDARY, STARTUP2, RECOVERING, ARBITER, ROLLBACK.
- 哪些因素可能会影响选举呢?
比如:
- 复制集的选举协议,例如在v4之前是pv0, v4开始为pv1;
- 心跳
- 成员权重
- 数据中心失联
- 网络分区
- 镜像读取(Mirrored Reads)注:MongoDBv4.4开始提供的功能,用来预热从节点最近读取过的数据。
如果你还期望对上述影响因素有更全面的认识,可以参考官方文档 - Factors and Conditions that Affect Elections
故障转移期间的回滚
当成员在故障转移后重新加入其复制集时,回滚将还原以前的主在数据库上的写操作。 本质上就是保证数据的一致性。
仅当主服务器接受了在主服务器降级之前辅助服务器未成功复制的写操作时,才需要回滚。 当主数据库作为辅助数据库重新加入集合时,它会还原或“回滚”其写入操作,以保持数据库与其他成员的一致性。
更多可以参考官方文档 - Rollbacks During Replica Set Failover
复制集中的OptLog
oplog(操作日志)是一个特殊的有上限的集合(老的日志会被overwrite),它保存所有修改数据库中存储的数据的操作的滚动记录。
什么是OptLog
MongoDB在主节点上应用数据库操作,然后将这些操作记录到optlog中。然后从节点通过异步进程复制和应用(数据同步)这些操作。在local.oplog.rs集合中,所有复制集成员都包含oplog的一个副本用来维护数据库的当前状态。
MongoDB 4.4支持以小时为单位指定最小操作日志保留期,其中MongoDB仅在以下情况下删除操作日志条目:
- oplog已达到配置的最大大小
- oplog条目早于配置的小时数
在设计OptLog时要考虑什么
看下MongoDB在设计OptLog时考虑了什么?这对我们在使用和配置optlog有很好的帮助。
查看操作日志的状态?
操作日志设置多大?默认设置是多大呢?
操作日志保存多久?
哪些情况需要设置更大的?
对操作慢的管理和设置?
更多可以参考官方文档 - Replica Set Oplog
复制集中的数据同步
复制集中的数据同步是为了维护共享数据集的最新副本,包括复制集的辅助成员同步或复制其他成员的数据。 MongoDB使用两种形式的数据同步:
- 初始同步(Initial Sync) 以使用完整的数据集填充新成员, 即全量同步
- 复制(Replication) 以将正在进行的更改应用于整个数据集, 即增量同步
初始同步(Initial Sync)
从节点当出现如下状况时,需要先进行全量同步
- oplog为空
- local.replset.minvalid集合里_initialSyncFlag字段设置为true
- 内存标记initialSyncRequested设置为true
这3个场景分别对应
- 新节点加入,无任何oplog,此时需先进性initial sync
- initial sync开始时,会主动将_initialSyncFlag字段设置为true,正常结束后再设置为false;如果节点重启时,发现_initialSyncFlag为true,说明上次全量同步中途失败了,此时应该重新进行initial sync
- 当用户发送resync命令时,initialSyncRequested会设置为true,此时会重新开始一次initial sync
intial sync流程
- 全量同步开始,设置minvalid集合的_initialSyncFlag
- 获取同步源上最新oplog时间戳为t1
- 全量同步集合数据 (耗时)
- 获取同步源上最新oplog时间戳为t2
- 重放[t1, t2]范围内的所有oplog
- 获取同步源上最新oplog时间戳为t3
- 重放[t2, t3]范围内所有的oplog
- 建立集合所有索引 (耗时)
- 获取同步源上最新oplog时间戳为t4
- 重放[t3, t4]范围内所有的oplog
- 全量同步结束,清除minvalid集合的_initialSyncFlag
复制(Replication)
initial sync结束后,接下来Secondary就会『不断拉取主上新产生的optlog并重放』,这个过程在Secondary同步慢问题分析也介绍过,这里从另一个角度再分析下。
- producer thread,这个线程不断的从同步源上拉取oplog,并加入到一个BlockQueue的队列里保存着。
- replBatcher thread,这个线程负责逐个从producer thread的队列里取出oplog,并放到自己维护的队列里。
- sync线程将replBatcher thread的队列分发到默认16个replWriter线程,由replWriter thread来最终重放每条oplog。
问题来了,为什么一个简单的『拉取oplog并重放』的动作要搞得这么复杂?
性能考虑,拉取oplog是单线程进行,如果把重放也放到拉取的线程里,同步势必会很慢;所以设计上producer thread只干一件事。
为什么不将拉取的oplog直接分发给replWriter thread,而要多一个replBatcher线程来中转?
oplog重放时,要保持顺序性,而且遇到createCollection、dropCollection等DDL命令时,这些命令与其他的增删改查命令是不能并行执行的,而这些控制就是由replBatcher来完成的。
注意事项
这部分内容源自:阿里巴巴在这块的技术专家张友东
initial sync单线程复制数据,效率比较低,生产环境应该尽量避免initial sync出现,需合理配置oplog,按默认『5%的可用磁盘空间』来配置oplog在绝大部分场景下都能满足需求,特殊的case(case1, case2)可根据实际情况设置更大的oplog。
新加入节点时,可以通过物理复制的方式来避免initial sync,将Primary上的dbpath拷贝到新的节点,直接启动,这样效率更高。
当Secondary上需要的oplog在同步源上已经滚掉时,Secondary的同步将无法正常进行,会进入RECOVERING的状态,需向Secondary主动发送resyc命令重新同步。
生产环境,最好通过db.printSlaveReplicationInfo()来监控主备同步滞后的情况,当Secondary落后太多时,要及时调查清楚原因。
当Secondary同步滞后是因为主上并发写入太高导致,(db.serverStatus().metrics.repl.buffer.sizeBytes持续接近db.serverStatus().metrics.repl.buffer.maxSizeBytes),可通过调整Secondary上replWriter并发线程数来提升。
复制集读写关注(concern)
读的优先级(Read Preference)
默认情况下,复制集的所有读请求都发到Primary,Driver可通过设置Read Preference来将读请求路由到其他的节点。
primary: 默认规则,所有读请求发到PrimaryprimaryPreferred: Primary优先,如果Primary不可达,请求Secondarysecondary: 所有的读请求都发到secondarysecondaryPreferred:Secondary优先,当所有Secondary不可达时,请求Primarynearest:读请求发送到最近的可达节点上(通过ping探测得出最近的节点)
Write Concern
默认情况下,Primary完成写操作即返回,Driver可通过设置Write Concern来设置写成功的规则。
如下的write concern规则设置写必须在大多数节点上成功,超时时间为5s。
db.products.insert(
{ item: "envelopes", qty : 100, type: "Clasp" },
{ writeConcern: { w: majority, wtimeout: 5000 } }
)
上面的设置方式是针对单个请求的,也可以修改副本集默认的write concern,这样就不用每个请求单独设置。
cfg = rs.conf()
cfg.settings = {}
cfg.settings.getLastErrorDefaults = { w: "majority", wtimeout: 5000 }
rs.reconfig(cfg)
参考文章
https://docs.mongodb.com/manual/replication/
https://www.cnblogs.com/clsn/p/8214345.html
https://cloud.tencent.com/developer/article/1004435
https://cloud.tencent.com/developer/article/1004384
https://mongoing.com/archives/72571